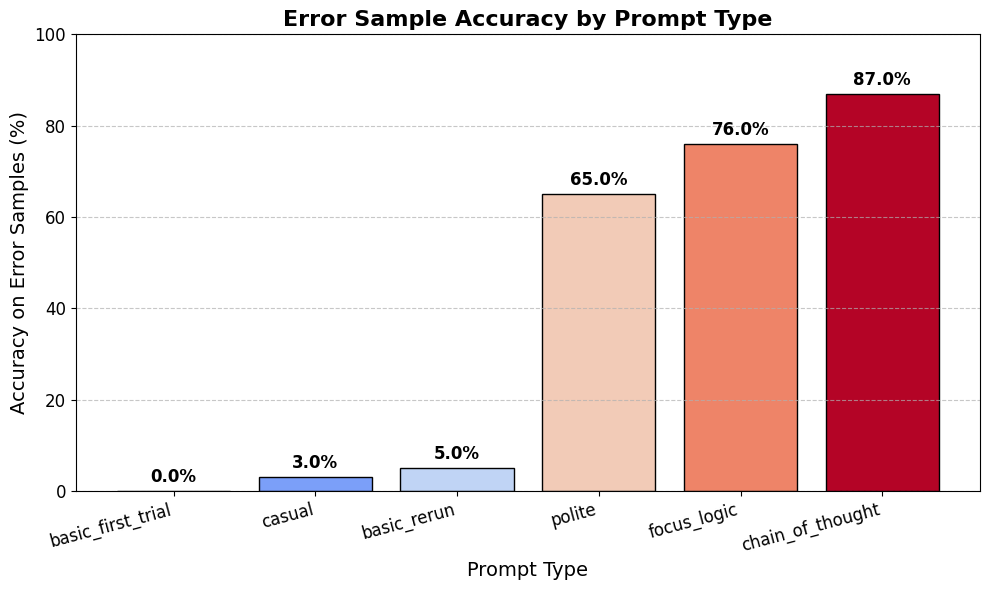
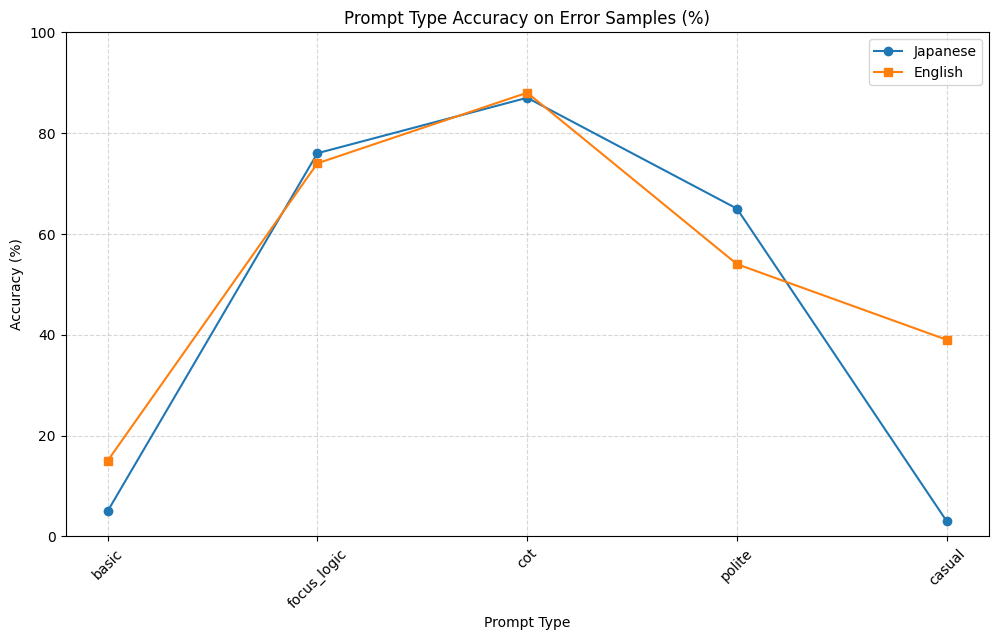
Dataset Overview
BIS Dataset Construction
The BIS dataset consists of 5,000 carefully constructed syllogistic reasoning problems designed to test the robustness of logical inference in LLMs under conditions of belief inconsistency. Each example comprises two premises and one conclusion that is strictly entailed by syllogistic rules, but deliberately conflicts with general knowledge.
Example from Dataset

This example illustrates a belief-inconsistent syllogism where the conclusion is logically valid but contradicts common real-world beliefs about ceramics and biomass fuel.
Dataset Categories

The dataset covers 46 distinct semantic categories, consolidated into 10 broader final categories including Human/Body/Senses, Animals/Organisms, Structure/Logic, and Natural Phenomena/Matter.